The Evolution of AI (Part 2): Large Language Models: The Unexpected Emergence of Intelligence
Discover how Large Language Models (LLMs) evolved from simple text prediction to sophisticated reasoning capabilities. Learn about emergent properties, GPT evolution, and the scaling paradox in AI.

What if I told you that a system trained to simply ‘predict the next word’ could write poetry, solve math problems, generate code, and even reason about complex topics? This isn't science fiction: it's the reality of Large Language Models (LLMs), where scale has unlocked capabilities that nobody explicitly programmed.
Read the Complete AI Evolution Series:
Part 1: The Evolution of AI: From Rule Books to Foundation Models
Part 2: Large Language Models: The Unexpected Emergence of Intelligence
Part 3: RAG: Teaching AI to Ground Its Knowledge in Realtime
Part 4: AI Agents: When LLMs Learn to Think, Remember, and Act
Large Language Models represent one of the most surprising developments in artificial intelligence. What started as a simple task, predicting the next word in a sequence, has evolved into systems that can understand context, reason about problems, and generate human like text across a vast range of topics.
Building on our previous discussion about the evolution from traditional AI to foundation models, LLMs represent a specific type of foundation model that demonstrates the power of large scale training on diverse text data. While foundation models can work with multiple data types, LLMs focus specifically on language, showing how scale can unlock unexpected capabilities.
The journey from basic text prediction to sophisticated reasoning capabilities shows us that sometimes, the most powerful breakthroughs come from unexpected places.

LLMs exhibit emergent abilities such as reasoning and multi step problem solving when the models are scaled with billions of parameters.
Introduction: More Than Just Next Word Prediction
The Deceptive Simplicity Of LLM Training
At first glance, training a Large Language Model seems straightforward: show it millions of text examples and teach it to predict what word comes next. This sounds like a simple pattern matching task, not the foundation for systems that can write essays, solve coding problems, or engage in complex conversations.
But here's the surprising part: when you scale this simple task to massive proportions, training on billions of words with models containing hundreds of billions of parameters, something remarkable happens. The model doesn't just learn to predict words; it learns to understand language, context, and even reasoning patterns.
This transformation from predict the next word to complex reasoning abilities is what researchers call emergent properties. These are capabilities that arise naturally from scale, even though they weren't explicitly programmed into the system.
The Emergence Paradox
The most fascinating aspect of LLMs is that many of their most impressive capabilities, like chain of thought reasoning, few shot learning, and creative writing, emerged as the models got larger and were trained on more data. While these capabilities weren't explicitly programmed, they developed through a combination of emergent behaviour, training data patterns, and architectural design choices.
The GPT Evolution Story
GPT-1 To GPT-4: The Scaling Journey
To understand how LLMs developed their remarkable capabilities, we need to look at the evolution of one of the most influential model families: GPT (Generative Pre-trained Transformer). The GPT series demonstrates how increasing model size and training data can unlock entirely new capabilities that weren't present in smaller versions.
The evolution of GPT models perfectly illustrates how scale unlocks new capabilities:
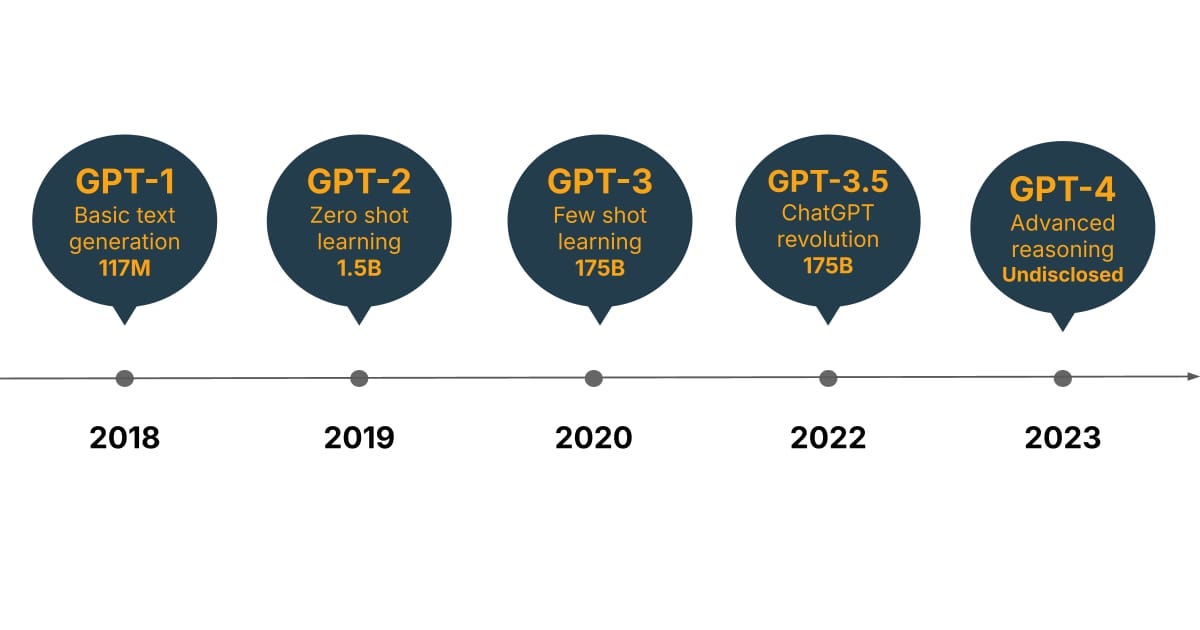
GPT Evolution Through Years
Model
Breakthrough Features
GPT-1
• First GPT model
• Complete sentences and short paragraphs
• Very limited context understanding
GPT-2
• Zero shot learning emerges
• Perform tasks without specific training
• Better grasp of context and style
GPT-3
• Few shot learning breakthrough
• Learn tasks from just a few examples
• Major leap in reasoning, coherence, and creativity
GPT-3.5
• Fine tuned GPT-3 with RLHF
• Better instruction-following
• Launched ChatGPT in Nov 2022
• Conversational abilities
• Mass adoption and mainstream awareness
GPT-4
• Multimodal capabilities (text and images)
• Advanced reasoning and problem-solving
• Near-human performance on many tasks
*Parameter count not officially disclosed by OpenAI
Key Breakthrough: The Dramatic Jump From GPT-2 To GPT-3
The most significant leap happened between GPT-2 and GPT-3, when the model size increased from 1.5 billion to 175 billion parameters, a 100x increase. This massive scaling unlocked capabilities that were barely present in the smaller model, including:
Few shot learning (learning from just a few examples)
Better reasoning and problem-solving.
More coherent and creative text generation.
Better ability to follow prompts.
ChatGPT Revolution And Mass Adoption
The release of ChatGPT in November 2022 marked a turning point in public awareness of AI capabilities. For the first time, millions of people could interact directly with a sophisticated language model, experiencing its capabilities firsthand. This led to rapid adoption across industries and sparked a new wave of AI development and investment.
Emergent Properties: Capabilities Nobody Programmed

Few Shot Learning And Chain Of Thought Reasoning
One of the most remarkable emergent properties is few shot learning: the ability to learn new tasks from just a few examples provided in the prompt. For example, you can show an LLM a few examples of how to translate between languages, and it will immediately start performing translations, even though it was never explicitly trained for translation.
Chain of thought reasoning is another emergent capability where the model breaks down complex problems into smaller steps, showing its reasoning process. While this capability emerged from the model's training, it was also influenced by the patterns in the training data and the model's ability to generalize from examples.
Multi-Task Capability And Code Generation
LLMs can perform a wide variety of tasks without specific training for each one. The same model that can write poetry can also:
Generate code in multiple programming languages
Solve math problems
Answer questions about history
Summarize documents
Translate between languages
This multi-task capability emerged from the model's exposure to diverse text data during training, allowing it to learn patterns that apply across many different domains.
Creative Writing And Complex Problem Solving
LLMs have also developed impressive creative capabilities, including:
Writing stories, poems, and scripts
Creating marketing copy and product descriptions
Generating ideas and brainstorming
Solving complex logic puzzles
These creative abilities weren't explicitly programmed but emerged from the model's understanding of language patterns, narrative structures, and human communication styles.
The Scaling Paradox: Power and Peril
More Capabilities Vs. More Sophisticated Hallucinations
As LLMs have become more powerful, they've also become more sophisticated in their mistakes. While early models might produce obviously wrong outputs, modern LLMs can generate convincing but incorrect information, a phenomenon known as hallucination.
This creates a paradox: the same capabilities that make LLMs so useful (coherent, creative text generation) also make their errors more dangerous because they're harder to detect.
The Balance Between Capability And Reliability
As LLMs become more powerful, ensuring they behave safely and align with human values becomes increasingly important. The same capabilities that make these models useful can also make their errors more sophisticated and harder to detect.
The challenge for LLM developers is finding the right balance between:
Capability: The model's ability to perform complex tasks
Reliability: The model's consistency and accuracy
Safety: The model's tendency to produce harmful or incorrect outputs
This balance is crucial for real world applications where accuracy and safety are paramount. Researchers are actively working on techniques to address these challenges, but the fundamental tension between capability and reliability remains a key consideration for anyone working with large language models.
Conclusion: The Foundation is Set
LLMs: Powerful But Limited
Large Language Models are a major breakthrough in AI, but they have key limitations:
No memory: They forget everything between conversations
No real-time data: Can't access current information
Reactive only: They respond to prompts but don't take initiative
No external access: Can't interact with databases or systems
The Knowledge Problem: LLMs are stuck with outdated training data. They can't answer questions about recent events or access your company's documents.
The next breakthrough will give LLMs access to real-world, up-to-date information. In our next article, RAG: Teaching AI to Ground Its Knowledge in Realtime, we'll explore how this works.
Found this helpful? Share it with a colleague who's curious about emergent AI capabilities. Got questions? We'd love to hear from you at [email protected]