Throttling Pattern: Controlling Request Rates for System Protection
Master the Throttling pattern with rate limiting algorithms, configuration strategies, with Java implementations for protecting systems from overload in distributed environments.

In distributed systems, uncontrolled request rates can overwhelm services and cause failures. The Throttling pattern protects systems by limiting how many requests a client can make within a given time window, ensuring fair resource allocation and system stability.
This pattern is essential for any service exposed to external clients such as APIs, microservices, or cloud functions, where you cannot fully control how callers behave. By implementing intelligent rate limiting, you prevent abuse, protect downstream dependencies, and maintain consistent performance for all users.

This guide walks you through the Throttling pattern from concept to practical implementation, covering the three core rate limiting algorithms, how to apply them in a real API service, and how to choose the right approach for your use case.
Understanding the Throttling Pattern
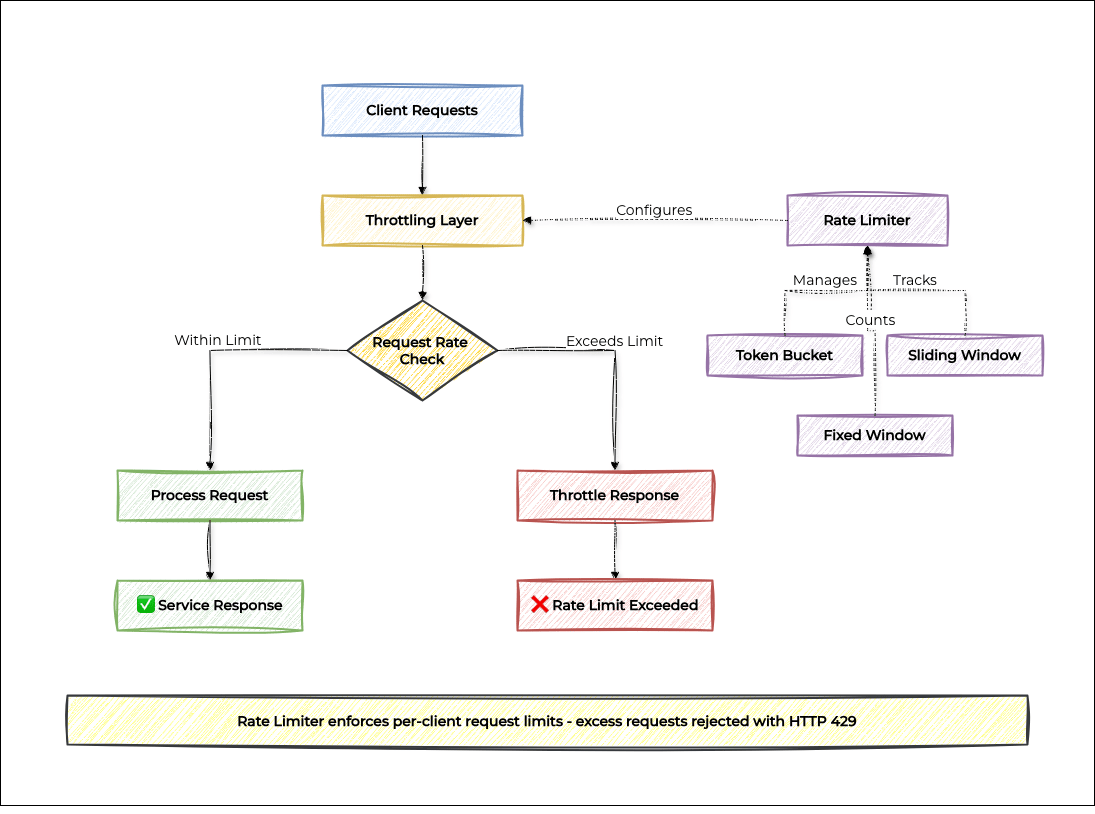
The Throttling pattern sits in front of your service and intercepts each incoming request. Before passing the request through, it checks whether the client has exceeded their allowed rate. If they have, the request is rejected with a rate limit error (typically HTTP 429) rather than forwarded to the service.
Core Throttling Strategies
Throttling Pattern Strategies
Key Benefits
System Protection: Prevents services from being overwhelmed by excessive requests.
Resource Management: Ensures fair allocation of system resources.
Cost Control: Prevents runaway costs from unexpected traffic spikes.
Quality of Service: Maintains consistent performance for legitimate users.
Abuse Prevention: Protects against malicious or accidental abuse.
Implementing the Throttling Pattern
Let's build a throttling system that implements three classic rate limiting algorithms, then applies one of them in a practical API service.
Implementation Overview
TokenBucketRateLimiter: The most flexible algorithm. Clients accumulate tokens over time and spend one per request, allowing short bursts while enforcing a long-term average rate.
SlidingWindowRateLimiter: The most accurate algorithm. Tracks the timestamp of every request and counts how many fall within the last N milliseconds, giving a precise rolling rate.
FixedWindowRateLimiter: The simplest algorithm. Counts requests per fixed time slot and resets the counter when the slot changes.
RateLimitedApiService: A practical API service that applies Token Bucket throttling per client.
Main: A runnable demo showing normal usage and burst traffic hitting the rate limit.
This implementation uses plain Java with no external dependencies. For production systems, consider using a distributed cache like Redis to share rate limit state across multiple service instances. An in-memory limiter only enforces limits on a single node.
Rate Limiting Algorithms
/**
* Token Bucket: imagine a bucket that fills with tokens over time.
* Each request consumes one token. If the bucket is empty, the request is rejected.
* Allows short bursts (up to capacity) while enforcing a steady long-term rate.
*/
public class TokenBucketRateLimiter {
private final int capacity; // Max tokens the bucket can hold (burst limit)
private final double refillPerMs; // Tokens added per millisecond
private final Map<String, Bucket> buckets = new HashMap<>();
public TokenBucketRateLimiter(int capacity, int refillPerSecond) {
this.capacity = capacity;
this.refillPerMs = refillPerSecond / 1000.0;
}
/** Returns true if the request is allowed, false if rate-limited */
public boolean isAllowed(String clientId) {
Bucket bucket = buckets.computeIfAbsent(clientId, k -> new Bucket(capacity));
bucket.refill();
return bucket.tryConsume();
}
private class Bucket {
private double tokens;
private long lastRefillTime = System.currentTimeMillis();
Bucket(int initialTokens) { this.tokens = initialTokens; }
/** Add tokens based on how much time has passed since the last refill */
void refill() {
long now = System.currentTimeMillis();
double tokensToAdd = (now - lastRefillTime) * refillPerMs;
tokens = Math.min(capacity, tokens + tokensToAdd);
lastRefillTime = now;
}
boolean tryConsume() {
if (tokens >= 1.0) {
tokens -= 1.0;
return true;
}
return false;
}
}
}
/**
* Sliding Window: tracks the timestamp of every recent request.
* Only counts requests that fall within the last windowMs milliseconds.
* Most accurate approach with no boundary artifacts, but uses more memory.
*/
public class SlidingWindowRateLimiter {
private final int maxRequests;
private final long windowMs;
private final Map<String, Queue<Long>> requestLogs = new HashMap<>();
public SlidingWindowRateLimiter(int maxRequests, long windowMs) {
this.maxRequests = maxRequests;
this.windowMs = windowMs;
}
public synchronized boolean isAllowed(String clientId) {
long now = System.currentTimeMillis();
Queue<Long> timestamps = requestLogs.computeIfAbsent(clientId, k -> new LinkedList<>());
// Drop timestamps that have slid outside the current window
while (!timestamps.isEmpty() && now - timestamps.peek() > windowMs) {
timestamps.poll();
}
if (timestamps.size() < maxRequests) {
timestamps.offer(now);
return true;
}
return false;
}
}
/**
* Fixed Window: counts requests within a fixed time slot (e.g., the current minute).
* Simplest to implement. Trade-off: a burst at a window boundary can send
* up to 2× the limit in a short period.
*/
public class FixedWindowRateLimiter {
private final int maxRequests;
private final long windowMs;
private final Map<String, Window> windows = new HashMap<>();
public FixedWindowRateLimiter(int maxRequests, long windowMs) {
this.maxRequests = maxRequests;
this.windowMs = windowMs;
}
public synchronized boolean isAllowed(String clientId) {
long currentSlot = System.currentTimeMillis() / windowMs;
Window window = windows.computeIfAbsent(clientId, k -> new Window(currentSlot));
// New time slot, reset the counter
if (window.slot != currentSlot) {
window.slot = currentSlot;
window.count = 0;
}
if (window.count < maxRequests) {
window.count++;
return true;
}
return false;
}
private static class Window {
long slot;
int count = 0;
Window(long slot) { this.slot = slot; }
}
}Practical Implementation: Rate-Limited API Service
/** An API service that enforces per-client rate limits using Token Bucket */
public class RateLimitedApiService {
private final TokenBucketRateLimiter rateLimiter;
public RateLimitedApiService(int requestsPerSecond) {
// Allow bursts up to 5 requests, then refill at the specified rate
this.rateLimiter = new TokenBucketRateLimiter(5, requestsPerSecond);
}
public ApiResponse handleRequest(String clientId, String operation) {
if (!rateLimiter.isAllowed(clientId)) {
System.out.println(" [" + clientId + "] THROTTLED: " + operation);
return new ApiResponse(429, "Rate limit exceeded. Slow down your requests.");
}
System.out.println(" [" + clientId + "] OK: " + operation);
return new ApiResponse(200, "Success");
}
}
// Simple data class for the API response
public record ApiResponse(int status, String message) {}Putting It All Together
public class Main {
public static void main(String[] args) throws InterruptedException {
// 2 requests/sec with a burst capacity of 5
RateLimitedApiService service = new RateLimitedApiService(2);
// Happy path: spread-out requests stay within the rate limit
System.out.println("=== Normal usage ===");
service.handleRequest("client-A", "GET /products");
Thread.sleep(600);
service.handleRequest("client-A", "GET /orders");
Thread.sleep(600);
service.handleRequest("client-A", "GET /profile");
System.out.println();
// Burst: 8 requests in quick succession exhaust the bucket and trigger throttling
System.out.println("=== Burst traffic ===");
for (int i = 1; i <= 8; i++) {
service.handleRequest("client-B", "GET /products (request " + i + ")");
}
}
}Example Output
=== Normal usage ===
[client-A] OK: GET /products
[client-A] OK: GET /orders
[client-A] OK: GET /profile
=== Burst traffic ===
[client-B] OK: GET /products (request 1)
[client-B] OK: GET /products (request 2)
[client-B] OK: GET /products (request 3)
[client-B] OK: GET /products (request 4)
[client-B] OK: GET /products (request 5)
[client-B] THROTTLED: GET /products (request 6)
[client-B] THROTTLED: GET /products (request 7)
[client-B] THROTTLED: GET /products (request 8)Choosing the Right Algorithm
All three algorithms limit request rates, but they behave differently at the edges:
Token Bucket is best when you want to allow short bursts. A client who hasn't sent requests in a while accumulates tokens they can spend all at once, then must wait for the bucket to refill. Use this when occasional spikes are acceptable and you want to reward clients who space out their requests.
Sliding Window is the most accurate and fairest. It counts exactly how many requests arrived in the last N seconds at any point in time, with no boundary effects. The trade-off is memory: it stores one timestamp per recent request. Use this when precision matters most.
Fixed Window is the simplest to understand and implement. The risk is the boundary burst: a client can fire maxRequests at 11:59:59 and another maxRequests at 12:00:00, that's 2× the limit in two seconds. Use this for non-critical limits where simplicity is preferred.
When to Use Throttling Pattern
✅ Ideal Scenarios:
Your API or service is called by external clients whose request behaviour you cannot fully control.
You need to protect downstream services from being flooded by a single misbehaving client.
You want fair resource allocation, preventing one client from monopolizing shared capacity.
You are enforcing business rules around tiered limits (free vs. paid plans).
You need to cap usage of an expensive downstream service or API to control costs.
You're building a public-facing API where abuse protection is required.
❌ Skip It When:
Your service is only called by internal, trusted systems with predictable and controlled request rates.
You need to guarantee processing of every request. Consider the Queue-based Load Leveling pattern instead.
The cost of dropped requests exceeds the cost of the overload you're trying to prevent.
All clients are coordinated and can implement cooperative rate limiting at the source.
You're in an early-stage prototype where operational complexity isn't yet warranted.
Best Practices
Return meaningful responses: Respond with HTTP 429 and include a Retry-After header so clients know when to try again. This turns a confusing failure into an actionable signal.
Key limiters per client, not globally: A single misbehaving client shouldn't degrade service for others. Use a per-client identifier such as user ID, API key, or IP address as the rate limit key.
Use multiple granularities: Per-second limits protect against bursts; per-minute or per-hour limits enforce usage quotas. Many production APIs enforce both simultaneously.
Log throttled requests: Don't silently discard them. Throttling events are valuable signals for capacity planning and for diagnosing client integration problems.
Plan for distributed deployments: An in-memory rate limiter only works on a single instance. For multi-node deployments, synchronize counters using a shared store like Redis so limits are enforced consistently across all nodes.
Start permissive, tighten gradually: It is much easier to lower limits after clients are integrated than to raise them once they've built assumptions around the current values. Start generous and adjust based on observed behaviour.
Found this helpful? Share it with a colleague who's struggling with system overload and performance issues. Got questions? We'd love to hear from you at [email protected]